how to use library(tidyverse)library(broom)library(ggplot)
setting up a simple linear model,
creating a scatterplot with a regression line
Intercept placeholder
Definitions
Q1. What is a Linear Regression Model?
To answer this question, we need to understand three terminologies, “linear”, “regression”, and “model”. The non-mathematical human-language answers would be:
A model can be seen as a mathematical representation of the relationship or association between two or more variables. It consists of two components, variables and parameters, or coefficients (they are the estimate of parameters) (Heumann et al., p.269). A model can also be considered as a mathematical construct that we use to interpret the mechanism of generating the observed data (Rencher et al., 2008, p.2).
Whether the model is linear or non-linear is indeed a broad and difficult question. Simply saying, it is determined by the parameters (or the coefficients), for example, if the parameter is \(β_1^{2}\) , the model is non-linear (Heumann et al., 2022, p.269).
Regression analysis is used to analyze a relationship between two or more variables in which one of the variables can be predicted or explained by the information given by the other variables (Mohr et al., 2022, p.302).
Q2. What is simple linear regression?
In a simple linear regression, there is only one variable, x, to predict the response of y. The model can be written as
\[y=b_0+b_1x+e\]
\(b_0\)is the intercept,\(b_1\)is the coefficient.
A regression line can be used to describe how the dependent variabley changes as independent variable x changes. The process of modeling is to find out the most “suitable” regression coefficients. In another word, to find the best fitted line among the data points, and draw a regression line that leads to the least squares of errors.
Part 2: Model Setup
Based on the given equation, let’s start to set up a simply linear regression
library(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.1 ✔ stringr 1.5.2
✔ ggplot2 4.0.0 ✔ tibble 3.3.0
✔ lubridate 1.9.4 ✔ tidyr 1.3.1
✔ purrr 1.1.0
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
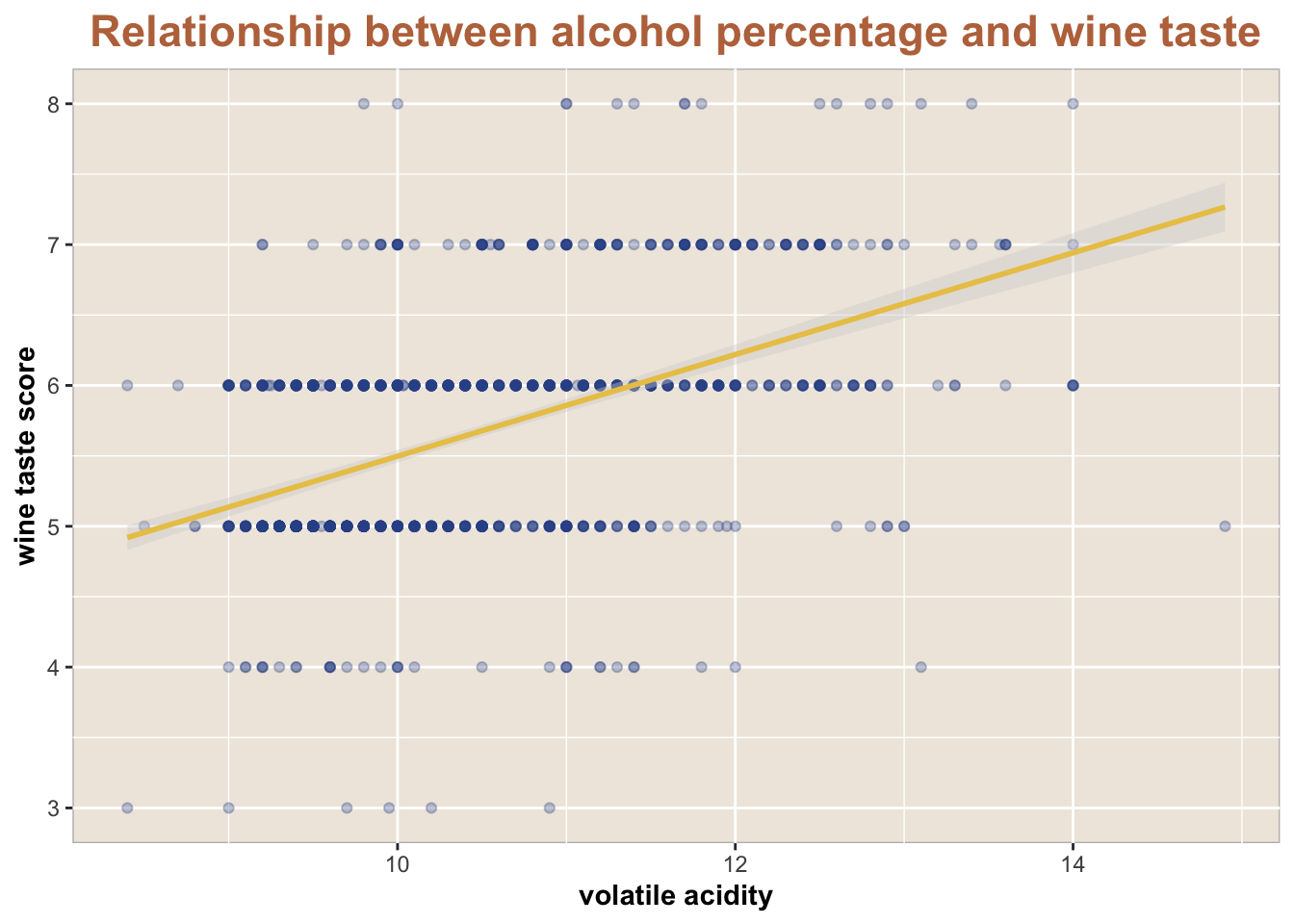
The First Model: The relationship between alcohol percentage in wine and wine taste
Background: The WineQuality.csv dataset was created to investigate the relationship between wine preference and wine physicochemical properties. The data was collected between 2004 and 2007. Samples all came from a unique type of Portugese wine vinho verde from the northwest region of Portugal. Each sample was tasted by three tasters, and the final sensory score was determined by the median of score of these tasters.
The document WineQuality.csv has 13 columns, in which, column 11 shows the percentage of alcohol in each sample (column name= ‘alcohol’, % VOL), column 12 shows the sensory score (column name=‘quality’ ) of the sample. When evaluating, score ranged from 0-10, 0 meant very bad 👎 , 10 meant excellent 🤤.
Rows: 1143 Columns: 13
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
dbl (13): fixed acidity, volatile acidity, citric acid, residual sugar, chlo...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
1 represents the intercept place holder. In R, the shorthand notation ‘y ~ x’ fits the model corresponding to the formula y ~ 1+x. The intercept is by default. Therefore, when building a null model, we use y ~ 1.
🐾 Step 3 - Produce a scatterplot of years of experience versus salary
By using geom_smooth(), we can plot a linear model by specifying the argument method='lm'.
The gray ribbon around the regression line is the ‘95% confidence interval’ (see Chapter 9)
ggplot(wine_quality,aes(x=alcohol,y=quality))+geom_point(alpha=0.3,color="#314F94")+geom_smooth(method='lm',formula = y ~ x,color='#EAC655',fill ="lightgrey")+labs(x="volatile acidity", y="wine taste score",title="Relationship between alcohol percentage and wine taste")+theme(plot.title =element_text(size =17, face ="bold",hjust =0.5, color ='#BC734A'),axis.title =element_text(size =11, face ="bold"),panel.background =element_rect(fill ="#EFE8DF", color ='grey'))
🐾 Step 4 - Retrieve information from the model
We can use fitted() to retrieve the model’s fitted values.
5.280798 is the prediction for the first data point.
Use summary() to get a coefficient table which includes useful summary statistics for the overall model fit.
summary(model1)
Call:
lm(formula = quality ~ alcohol, data = wine_quality)
Residuals:
Min 1Q Median 3Q Max
-2.8224 -0.4000 -0.1725 0.5152 2.5748
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.88701 0.20240 9.323 <2e-16 ***
alcohol 0.36104 0.01928 18.727 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.7051 on 1141 degrees of freedom
Multiple R-squared: 0.2351, Adjusted R-squared: 0.2344
F-statistic: 350.7 on 1 and 1141 DF, p-value: < 2.2e-16
#summary(model1)$r.squared
Use coef() to retrieve the coefficients of a linear model. The output is a vector.
coef(model1)
(Intercept) alcohol
1.887013 0.361041
coef(model1)[1]
(Intercept)
1.887013
# alternative way of indexing by namecoef(model1)['alcohol']
alcohol
0.361041
# Calculate the fitted value for an x-value of 11coef(model1)['(Intercept)'] +coef(model1)['alcohol']*11
(Intercept)
5.858464
🐾 Step 5 - Using the setup model to predict values
Alternatively, we can also generate predictions for a given sequence of numbers by using predict() .
Note
predict(object, newdata)
seq(from= , to= , by= )
# Generate prediction for a sequence of numbers by using the modelalcohol_values<-seq(from=11, to=13, by=0.2)mypreds<-tibble(alcohol=alcohol_values)mypreds$score<-predict(model1,newdata=mypreds)mypreds
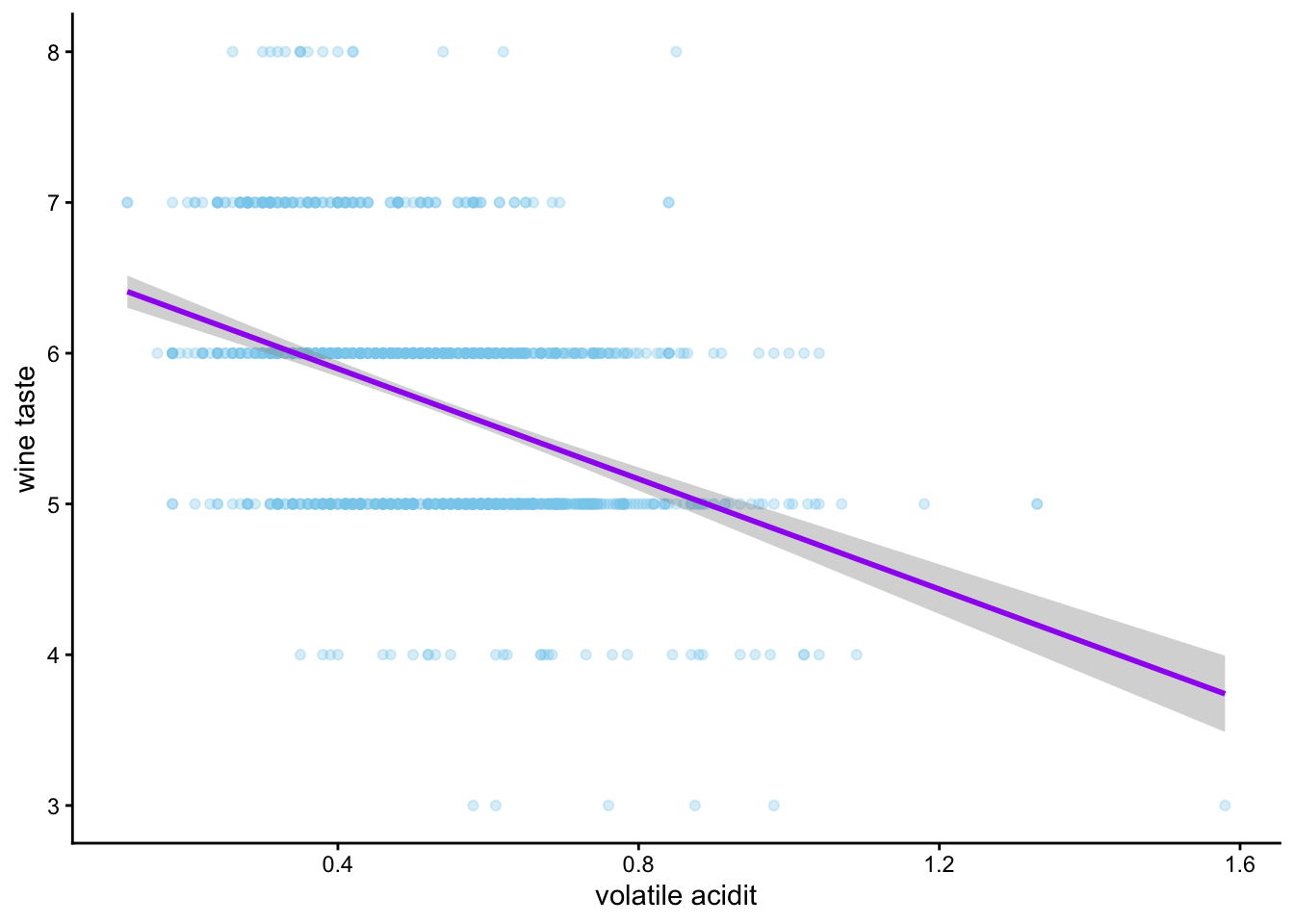
The Second Model: The relationship between volatile acidity in wine and wine taste
Now let’s use set up another simple linear model by using library(broom).
This time we want to look into the relationship between volatile acidity and wine taste.
Fun fact: What is Volatile Acidity (VA)? 🍷
VA measures the of amount of acids in wine that evaporate easily (mainly acetic acid). Excessive levels of VA will effect the taste of the wine and are considered as a wine fault. A small amount can add complexity. It is a key quality control measure in winemaking.
VA Unit: g(acetic acid)/dm3, means grams of acetic acid per cubic decimeter
🐾 Step 1 - Load data, set up a null model
newdf<-tibble(wine_quality$`volatile acidity`, wine_quality$quality)null_model2 <-lm(wine_quality$quality~1, data=newdf)null_model2 # Null model gives us the mean of y
Instead of using summary(), we can use tidy() to provide a model output. The advantage of using tidy()is that its output is a data frame, which allows you to easily index the relevant columns.
A regression line represents a model of conditional mean, specified by slope and intercept.
Coefficients are the principal outcomes of any regression analysis, allowing to make predictions.
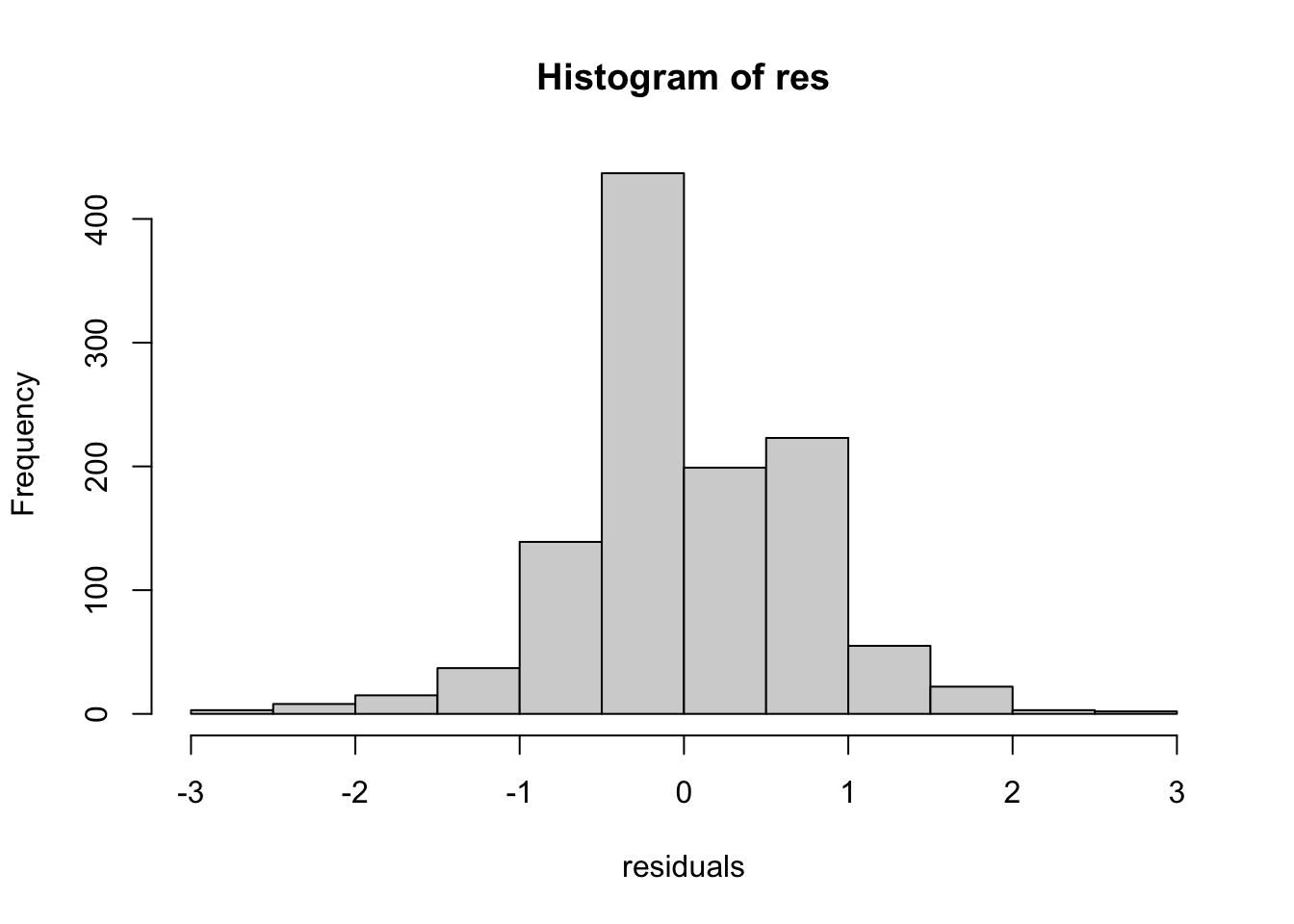
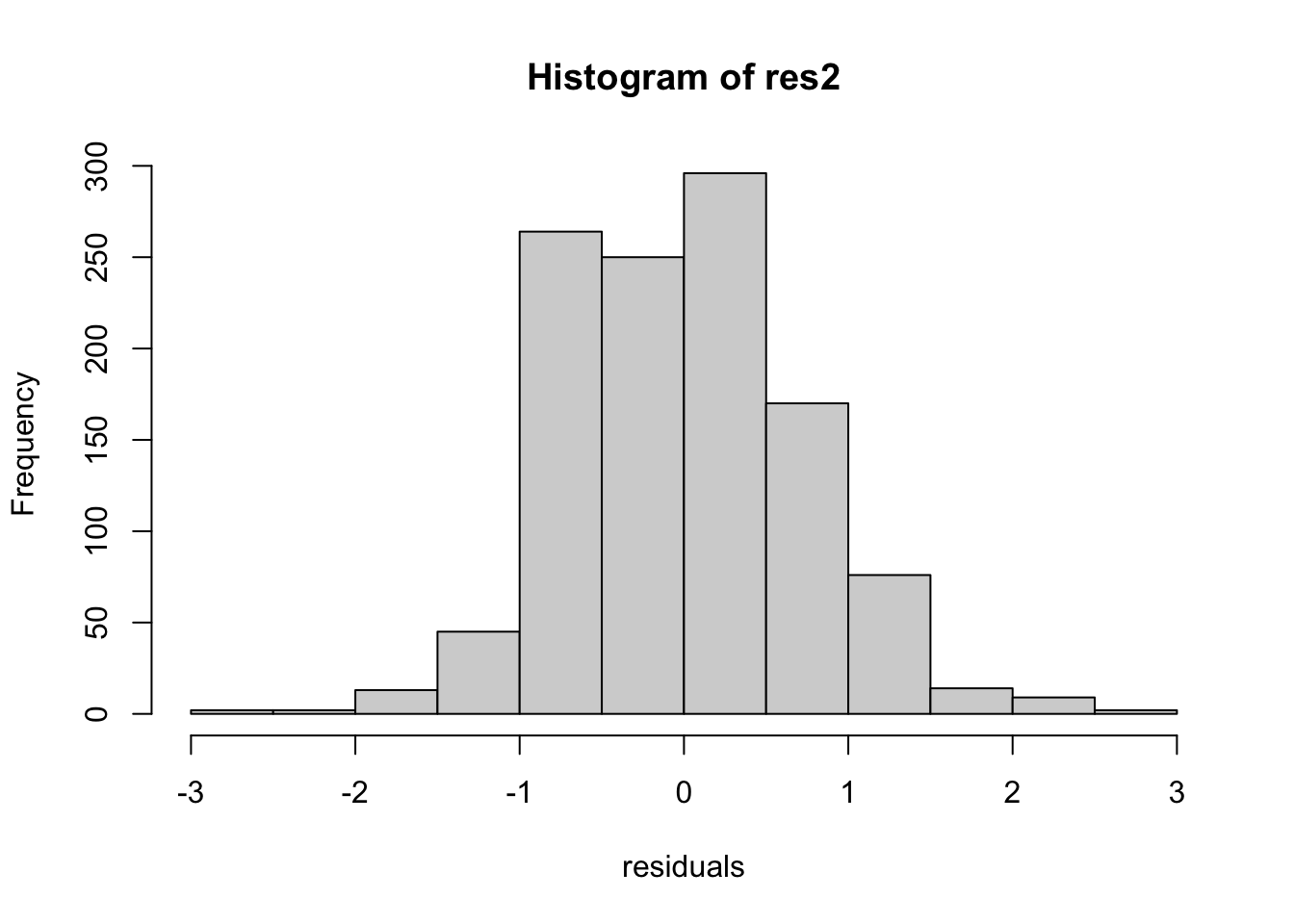
Residuals means the extent by which the observed data points deviate from the fitted values. They are assumed to be normally distributed and homoscedastic (constant variance)
\(R^2\) can be used to evaluate the model performance. It compares the model’s residuals to a null model’s residuals.
References
Heumann, C., Schomaker, M., & Shalabh. (2022). Introduction to statistics and data analysis: with exercises, solutions and applications in R (Second edition.). Springer. https://doi.org/10.1007/978-3-031-11833-3
Mohr, D. L., Wilson, W. J., & Freund, R. J. (2022). Linear regression. In D. L. Mohr, W. J. Wilson, & R. J. Freund (Eds.), Statistical methods (4th ed., pp. 301–349). Academic Press. https://doi.org/10.1016/B978-0-12-823043-5.00007-2
Rencher, A. C., Schaalje, G. B., & Wiley InterScience. (2008). Linear models in statistics (2nd ed.). Wiley-Interscience.r