Check out a similar explanation using the palmerpenguins data set here.
Categorical predictor variables
Categorical variables often include groups or categories (e.g., treatment vs. control; high proficiency vs. low proficiency). The values are stored as text, not numbers.
Terminology
categorical variable: the name of the entire variable
levels: the different values in the categorical variable
Hypothetical example: “The variable text-type is a categorical variable with two levels: simple and complex”
Important
A categorical variable can have more than two levels - in fact it can have as many as you like! Can you think of an example of a categorical variable with more than two levels?
Questions
How does a regression model deal with the different levels of categorical variables?
How does it turn text into numbers?
The default - dummy coding
The default way that R handles categorical variables is referred to as dummy coding or also treatment coding. This means that one of the levels of the categorical variable because the baseline level of the category. What does that mean? We know that continuous variables are set to 0 to serve as a baseline starting point (and that one reason to z-score or center is to set these variables at their means).
Setting a level as the baseline in a categorical variable is the same as setting a continuous predictor to zero. Literally - the level is replaced with the numerical value of 0.
Let’s look at the data BW used:
library(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.1 ✔ stringr 1.5.2
✔ ggplot2 4.0.0 ✔ tibble 3.3.0
✔ lubridate 1.9.4 ✔ tidyr 1.3.1
✔ purrr 1.1.0
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
dat <-read_csv('winter_2016_senses_valence.csv')
Rows: 405 Columns: 6
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (2): Word, DominantModality
dbl (4): Val, AbsVal, Sent, AbsSent
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Here we are interested in the categorical variable of sensory modality. Let’s look at the variable: how many different levels are there? We can do this a number of ways, but table() is a quick base R function to grasp an immediate overview
table(dat$DominantModality)
Sight Smell Sound Taste Touch
198 25 67 47 68
We accomplish the same thing as summary(), however we also have to recast the variable into a factor first, as it is stored as text data
summary(as.factor(dat$DominantModality))
Sight Smell Sound Taste Touch
198 25 67 47 68
When not using it as a factor, the column is just text. One nice thing is that when inputting this variable into a regression model, it will be handled automatically as a categorical variable with levels associated to each unique value in the data.
summary(dat$DominantModality)
Length Class Mode
405 character character
Taste and Smell
BW is interested in the taste and smell values only, let’s filter those:
dat2 <- dat %>%filter(DominantModality %in%c("Taste", "Smell"))
Calculate the mean and standard deviation of Val (the dependent variable, which is the sentiment of the word’s semantic contexts, positive or negative). Yay, we get the same results as the book.
Let’s just fit the model first then unpack what is going on.
m1 <-lm(Val ~ DominantModality, data = dat2)
Interpreting the intercept
What does the intercept mean in this model? If we know that R is setting DominantModality to its reference level, then the intercept should be…? Hint: look at the descriptive statistics calculated before the model.
summary(m1)
Call:
lm(formula = Val ~ DominantModality, data = dat2)
Residuals:
Min 1Q Median 3Q Max
-0.99315 -0.20870 0.04343 0.19115 0.62788
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 5.47101 0.06297 86.889 < 2e-16 ***
DominantModalityTaste 0.33711 0.07793 4.326 4.95e-05 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.3148 on 70 degrees of freedom
Multiple R-squared: 0.2109, Adjusted R-squared: 0.1997
F-statistic: 18.71 on 1 and 70 DF, p-value: 4.951e-05
Interpreting the coefficient
If we know that the intercept is the average value of Val when DominantModality is held at its reference level (i.e., Smell), then what does the coefficient mean?
The answer is that we interpret this as we would a continuous coefficient. The estimate is the change in the intercept when going from Smell to Taste. All we can do is compare the mean values of Val between these two levels of the variable. Let’s verify this
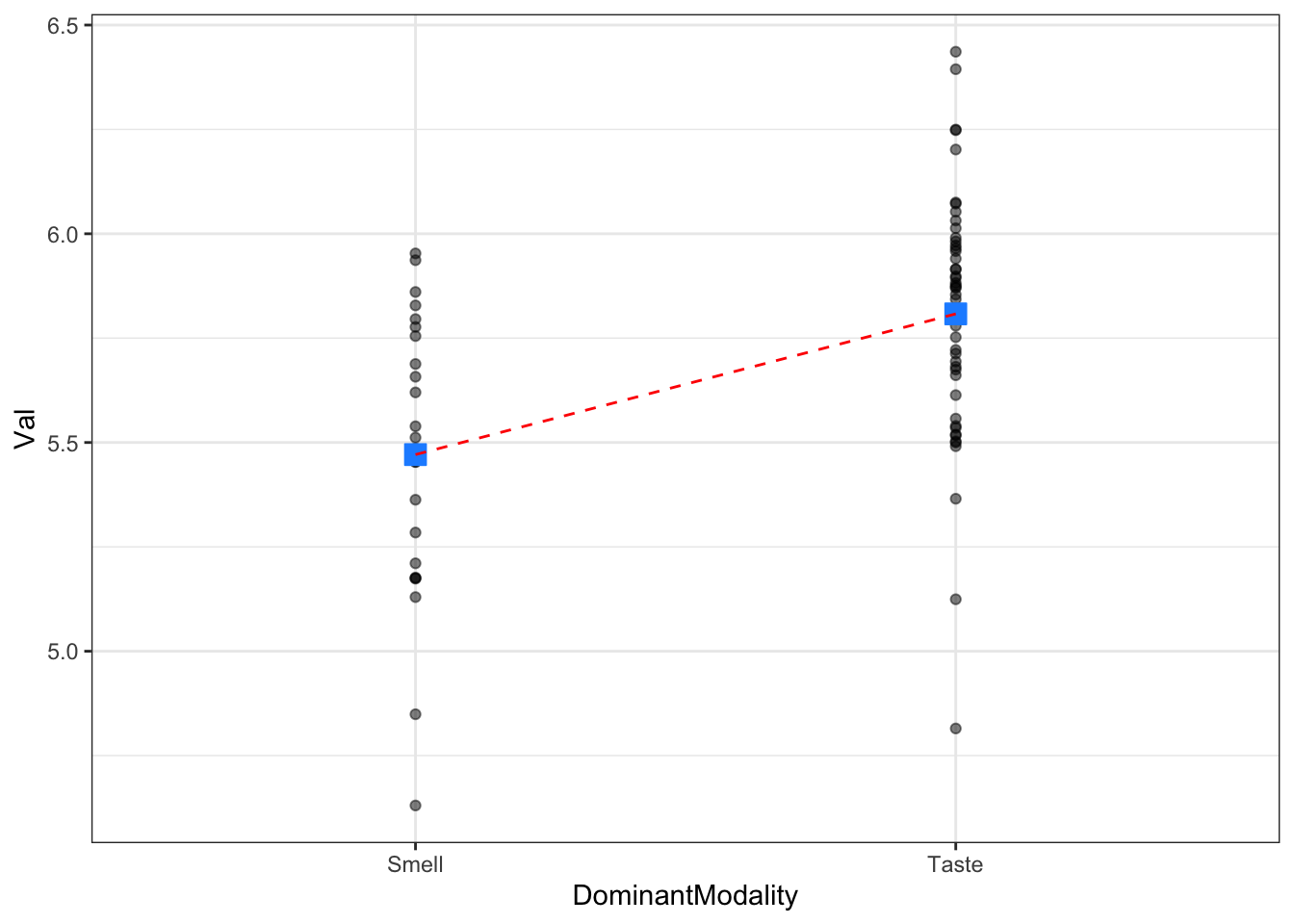
Mean for Smell, the baseline, is identical to the model intercept:
Smell is the intercept, and going to taste represents a one unit increase in the variable DominantModality. The slope (red-dotted line) is the coefficient, showing that going from Smell to Taste changes Val by 0.33.
Contrast coding
The technical term for what is going on here is known as contrast coding. We can check the default levels and their contrasts of any variable by using the contrasts function, but we do need to change it into a factor first.
Look - the contrasts for dummy coding have simply give the reference level, Smell, a value of 0, whereas Taste has a value of 1. The maths underneath now use those numbers when including this variable as a predictor.
contrasts(as.factor(dat2$DominantModality))
Taste
Smell 0
Taste 1
more than 2 levels?
This should give you a basic understanding of how categorical variables are turned into numbers! But what if we have a category with more than 2 levels? No problem, dummy coding still works fine. Let’s see what happens to the entire set of levels for DominantModality. What is going on here?
It’s a bit confusing, to be honest. But we see that Sight has all zeros, and there is no column for sight. This is our baseline level. For each column, the variable for that column has a 1, showing that it will be compared to the baseline. This means with dummy / treatment coding, all non-baseline levels are compared to the baseline level, and that’s it. Any further comparisons require unpacking the pairwise contrasts using a library like emmeans, which we will get to later.